NeuroVault
A persistent, local-first memory layer for AI agents. Sits between your local markdown vault and any MCP-compatible agent (Claude Code, Claude Desktop, Cursor, Codex) — giving them a callable recall() + remember() surface that persists forever, with no cloud, no subscription, no Python sidecar.
build neurovault --releaseReady Stack resolved in 0.23s
[+] loaded dependency: Tauri 2
[+] loaded dependency: Rust
[+] loaded dependency: React 19
[+] loaded dependency: TypeScript
[+] loaded dependency: SQLite + sqlite-vec
[+] loaded dependency: fastembed (BGE-small)
[+] loaded dependency: Axum HTTP
[+] loaded dependency: MCP
[+] loaded dependency: FastMCP proxy01 / What it is.
Modern chat assistants have no native long-term memory. Every new session starts from zero. NeuroVault fixes that — without sending anything to a cloud service.
It is
- A single ~9 MB binary you install once.
- A local markdown vault that is the source of truth (rebuildable from disk).
- An MCP server agents can call to remember and recall — over loopback HTTP.
- An in-process Rust retriever: hybrid semantic + BM25 + graph with optional cross-encoder rerank.
It is not
- A cloud RAG service. Everything runs on your machine.
- A general-purpose vector DB. It's a memory system for markdown + typed metadata.
- Trying to beat academic benchmarks. It optimises for single user, many agents, no cost per ingest, under 100 ms per recall.
- A Python app. The whole hot path lives in Rust in-process.
02 / Architecture.
One process. The React UI talks to the Rust memory layer via Tauri IPC; external agents talk to the same memory layer over loopback HTTP via a thin FastMCP proxy. The single most important architectural choice: the heavy stuff never runs in the agent's process tree.
┌─────────────────────────────────────────────────────────────────────┐
│ NeuroVault.exe (Tauri, single process, ~35 MB idle) │
│ │
│ ┌──────────────────┐ ┌──────────────────────────────────────┐│
│ │ React UI │◄─────►│ Rust memory::* modules (in-process) ││
│ │ • sidebar │ Tauri │ • retriever (hybrid + rerank) ││
│ │ • editor │ IPC │ • ingest (chunk/embed/link/BM25) ││
│ │ • graph view │ │ • file watcher (notify crate) ││
│ │ • command palt. │ │ • SQLite + sqlite-vec ││
│ │ • settings │ │ • fastembed (BGE-small + rerank) ││
│ └──────────────────┘ └───┬──────────────────────────────────┘│
│ │ │
│ axum HTTP server (127.0.0.1:8765) │
└─────────────────────────────────┼───────────────────────────────────┘
│ loopback HTTP
┌───────────────┴────────────────┐
│ mcp_proxy.py (~30–50 MB) │
│ FastMCP stdio → HTTP shim │
└───────────────┬────────────────┘
│ stdio JSON-RPC
▼
┌────────────────────────────────┐
│ Claude Code · Cursor · Desktop │
└────────────────────────────────┘WebView2 is already on Windows — no shipping a second browser. Installer drops from 150 MB to 9.
Python had two: desktop + sidecar. Two fastembed loads, two SQLite connections, two sources of truth. The Rust version collapses them — memory runs inside the Tauri process.
UI hits memory via Tauri IPC; agents hit memory via loopback HTTP. Both call the same hybrid_retrieve_throttled. One implementation, two transports.
03 / How recall works.
A retrieval query runs through three signal sources fused into one ranked list. Optionally a cross-encoder reranks the top-K for precision-critical paths.
- 01Semantic recall (BGE-small + sqlite-vec)
Query is embedded with title-prefixed context, scored against the chunk vector index. Returns top 30.
- 02BM25 keyword recall
Independent lexical index over chunks catches exact-token matches the semantic index misses (rare names, code symbols, IDs).
- 03Graph traversal
Typed edges (semantic similarity / entity mention / wikilink) propagate scores between linked engrams — surfaces context the query didn't ask for but needs.
- 04Fusion + optional rerank
Reciprocal-rank-fusion produces a single ranking. Cross-encoder rerank is opt-in:
~680 mstotal instead of25 ms, but boosts hit@1 from 86.67% → 93.33%.
04 / Inside the app.
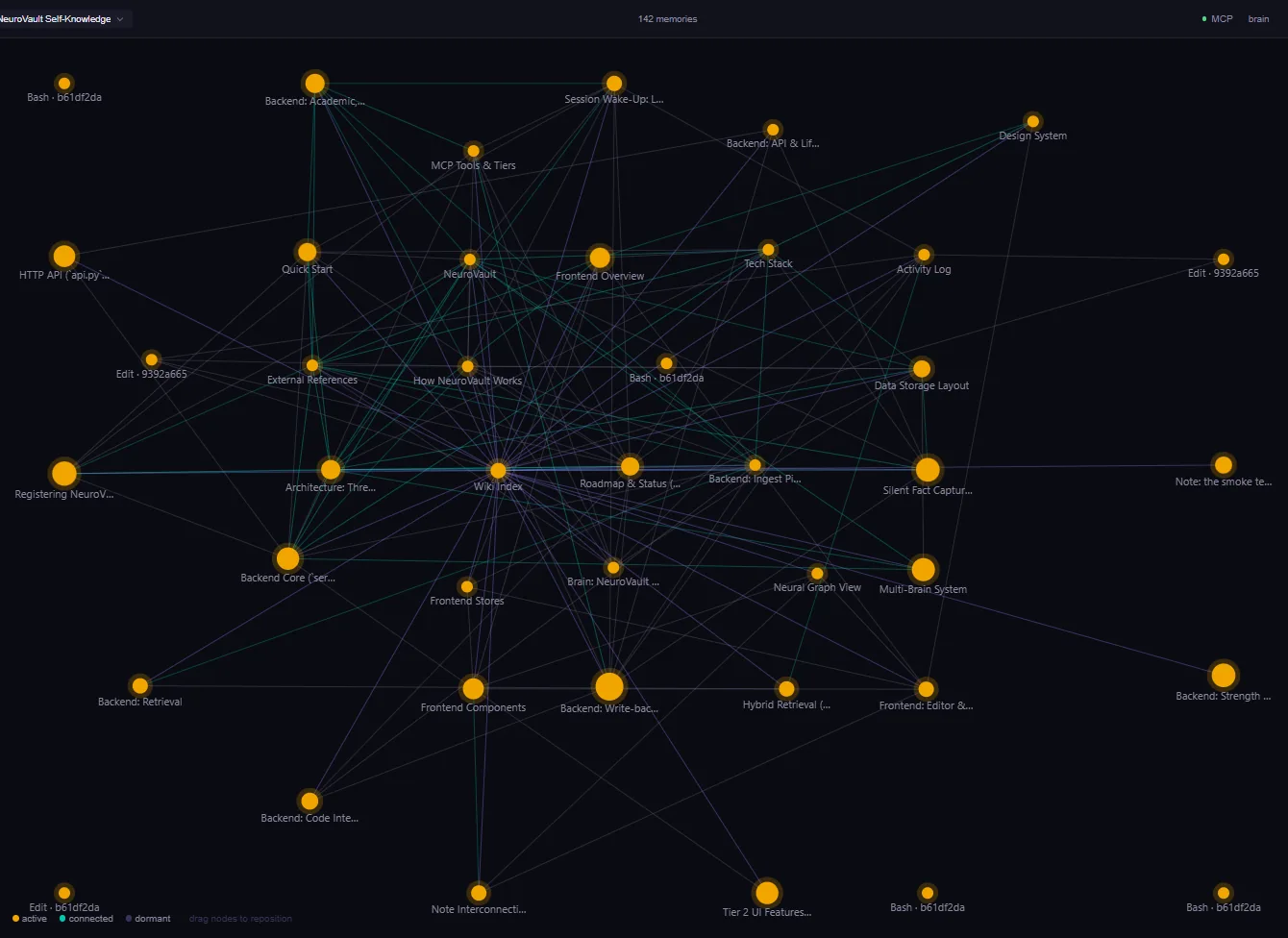
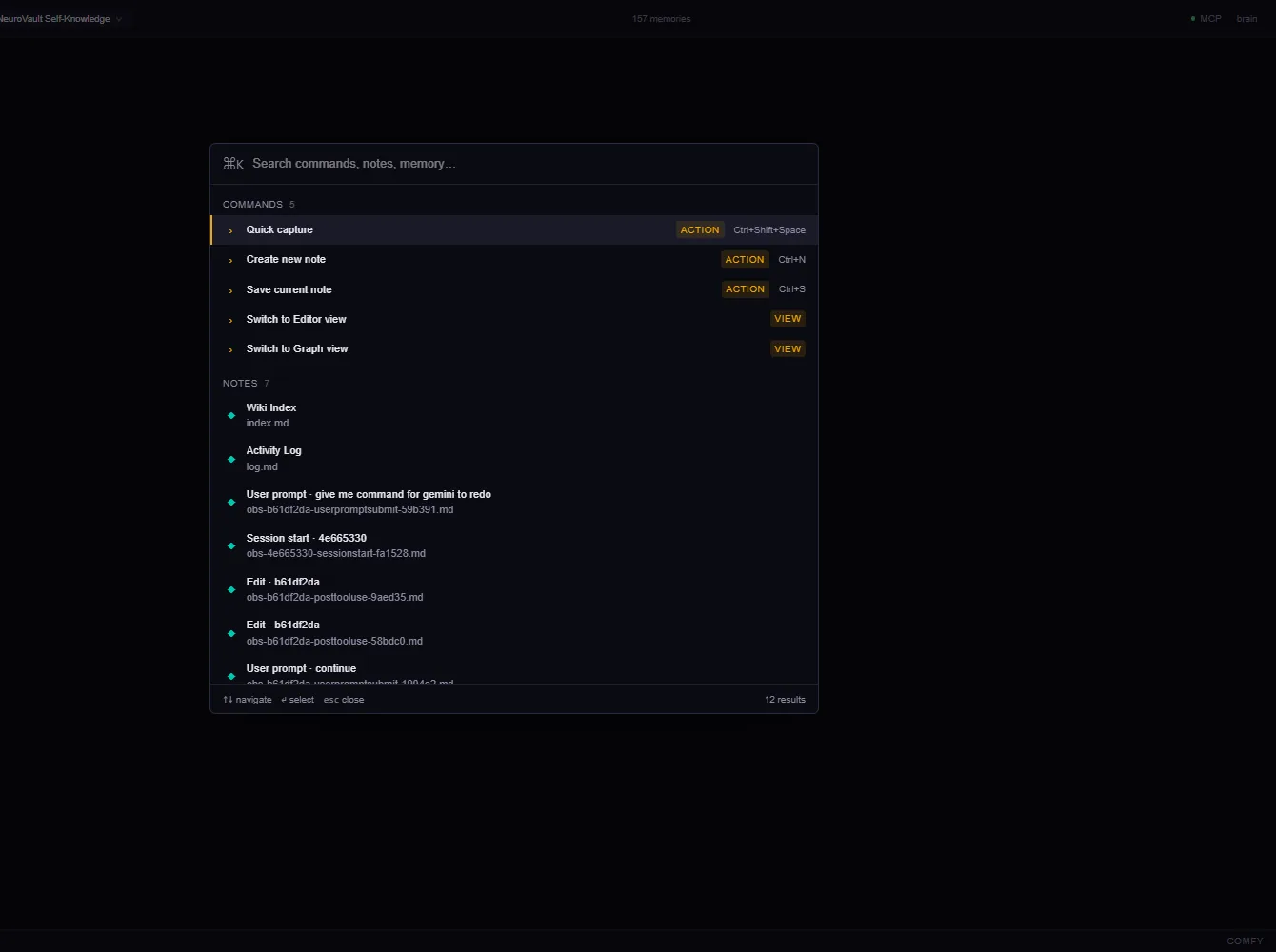
The UI is built around three primary surfaces: the markdown editor (boring on purpose), the command palette (where agents' memory operations show up), and the knowledge graph (the only place the hidden links between notes become visible).
05 / On disk.
Everything persists under ~/.neurovault/. Markdown files are the source of truth — if brain.db is ever deleted, it's rebuilt deterministically by re-ingesting every .md in the vault. This is a hard invariant: no memory exists only in the database.
~/.neurovault/
├── brains.json ← which brain is active
├── extensions/
│ └── vec0.dll ← sqlite-vec binary
└── brains/
└── <brain_id>/
├── brain.db ← SQLite: 24 tables (engrams,
│ chunks, vec_chunks, entities,
│ links, temporal_facts, …)
├── audit.jsonl ← append-only tool-call log
├── trash/ ← soft-deleted files
└── vault/
├── *.md ← markdown (source of truth)
├── index.md ← auto-maintained wiki index
└── log.md ← append-only activity feedTry it.
The full marketing site, downloads, and docs live at neurovault.dathproject.com. The source — Rust + React + Tauri, MIT licensed — is on GitHub.